基于Hadoop、Spark与Kafka的淘宝电商大数据推荐系统与情感分析
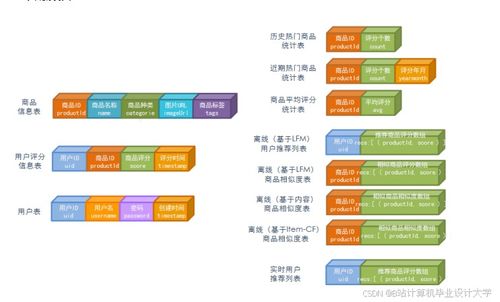
随着电子商务的快速发展,淘宝等平台积累了海量的用户行为数据和商品评论数据。如何从这些大数据中挖掘有价值的信息,实现个性化推荐和情感分析,成为电商平台提升用户体验和销量的关键。本毕业设计基于Hadoop、Spark、Kafka和Hive等技术,构建一个完整的淘宝电商大数据处理与分析系统,涵盖商品推荐、评论情感分析、数据可视化及系统服务功能。
一、系统架构与技术选型
本系统采用分层架构设计,包括数据采集层、数据处理层、数据分析层和应用服务层。
- 数据采集层:利用Kafka作为消息队列,实时收集淘宝用户行为数据(如浏览、点击、购买记录)和商品评论数据。
- 数据处理层:使用Hadoop的HDFS存储海量数据,并通过Hive进行数据清洗和预处理,构建数据仓库。
- 数据分析层:基于Spark的MLlib和Spark Streaming实现实时和离线分析。Spark用于商品推荐算法的训练(如协同过滤、基于内容的推荐),以及评论情感分析(使用自然语言处理技术识别正面、负面情感)。
- 应用服务层:通过Web服务提供推荐结果和情感分析报告,并利用可视化工具(如ECharts或Tableau)展示电商数据趋势、用户行为热图和情感分布。
二、核心功能模块
- 淘宝商品推荐系统:基于用户历史行为和商品属性,采用协同过滤和深度学习模型,生成个性化推荐列表。系统能实时更新推荐结果,适应动态用户偏好。
- 淘宝商品评论情感分析:对商品评论进行情感倾向分析,帮助商家了解用户反馈,优化产品和服务。使用Spark NLP库进行文本预处理和情感分类,输出情感评分和关键词提取。
- 电商推荐系统整合:将推荐与情感分析结合,例如,根据情感分析结果调整推荐权重,优先推荐高评价商品。
- 淘宝电商可视化:通过仪表盘展示用户行为数据、推荐效果指标和情感分析结果,支持多维度查询和交互式分析,便于决策者洞察趋势。
- 计算机系统服务:系统部署在分布式集群上,确保高可用性和可扩展性。使用Docker容器化技术管理服务,并通过监控工具(如Prometheus)实时跟踪系统性能。
三、实现流程与优势
实现流程包括数据导入(通过Kafka和Flume)、数据预处理(Hive SQL)、模型训练(Spark ML)、结果存储(HBase或MySQL)和前端展示。优势在于:
- 实时性:Kafka和Spark Streaming支持实时数据处理,提升推荐和情感分析的响应速度。
- 可扩展性:Hadoop和Spark的分布式架构轻松处理TB级数据。
- 准确性:通过多算法融合和情感分析优化推荐精度,提高用户满意度。
- 实用性:系统可直接应用于电商场景,帮助平台提升转化率和用户粘性。
四、总结与展望
本系统整合了大数据处理、机器学习和可视化技术,为淘宝电商提供了全面的数据驱动解决方案。未来可扩展更多功能,如引入图计算优化推荐、集成深度学习模型提升情感分析准确率,或结合云计算服务进一步降低成本。通过本毕业设计,学生可以深入掌握大数据生态系统,为职业生涯奠定坚实基础。
如若转载,请注明出处:http://www.xgkchina.com/product/14.html
更新时间:2026-06-03 05:45:19









